

Clustering US Laws using TF-IDF and K-Means
Hello, World.
Since I’m doing some natural language processing at work, I figured I might as well write my first blog post about NLP in Python. Inspired by the view of The Capitol from my apartment’s window (and fueled by Spotify and a couple of Golden Monkeys), I decided to use US laws for this post. Unfortunately, I couldn’t find a repository with the text of every US law – so I decided to create one myself by scraping laws from www.congress.gov. Anyone can download it from the Github repository for this post.
Scraping www.congress.gov with BeautifulSoup
First, I needed to scrape the legislation page to get the links for each bill. Each page has 25 bills on it, among other things. The URL ending of ?q=%7B"bill-status"%3A"law"%7D filters the results to only be enacted bills (bills that became law). By looking at a few of the pages, I noticed that the hyperlinks I need are essentially in the same place on every page (inside <h2> within an <ol> tag of class results_list).
So I can scrape all the hyperlinks with a nested loop. The outer loop grabs the data in the table on each page, and the inner loop extracts the hyperlinks for bills. Out of respect for www.congress.gov’s servers, I store the links in a list and write the list to a text file so I don’t have to scrape them again.
from __future__ import division
import re
import nltk
from nltk.corpus import stopwords
import bs4
import urllib2
import time
import pickle
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.stem.porter import PorterStemmer
# Get the hyperlinks for all of the bills
base_law_url = 'https://www.congress.gov/legislation?q=%7B"bill-status"%3A"law"%7D&page='
relevant_links = []
data_path = '~/clustering_laws/'
for i in xrange(1, 150):
print 'Page {0}'.format(i)
response = urllib2.urlopen(base_law_url + str(i))
html = response.read()
soup = bs4.BeautifulSoup(html)
tags = soup.find('ol', {'class' : 'results_list'})
h2_list = tags.find_all('h2')
for j in xrange(0, len(h2_list)):
#print j
href = h2_list[j].find('a').decode().encode('utf-8')
m = re.search('href="(.+)">', href)
if m:
relevant_links.append(m.group(1))
with open(data_path + 'law_links.txt', 'w') as handle:
for link in relevant_links:
handle.write("%s\n" % link)
With the hyperlinks to few thousand enacted bills in relevant_links, I next need to download the actual bills. By looking at a few of the pages, I noticed that access to the text version of the bills (instead of the PDF) is controlled by the URL ending /text?format=txt. On each page, the text stored in a <pre> tag with id billTextContainer.
By looping through relevant_links, I grab the title and text of each bill and store them in titles_list and bills_text_list. I’ll zip them into a the dictionary bills_dictionary with the titles as keys and text as values.
# Get the text and titles of the bills
titles_list = []
bills_text_list = []
text_ending = '/text?format=txt'
html_tags_re = re.compile(r'<[^>]+>')
def remove_html_tags(text):
return html_tags_re.sub('', text)
for i in xrange(len(relevant_links)):
print i
response = urllib2.urlopen(relevant_links[i] + text_ending)
html = response.read()
soup = bs4.BeautifulSoup(html)
# text
text_tags = soup.find('pre', {'id' : 'billTextContainer'})
if text_tags:
text = text_tags.decode().encode('utf-8')
text = remove_html_tags(text)
bills_text_list.append(text)
# titles
title_soup = soup.find('h1', {'class' : 'legDetail'})
title_soup = title_soup.decode().encode('utf-8')
st = title_soup.find('">') + len('">')
end = title_soup.find('<span>')
titles_list.append(title_soup[st:end])
bills_dictionary = dict(zip(titles_list, bills_text_list))
with open(data_path + 'bills_dictionary.pickle', 'wb') as handle:
pickle.dump(bills_clean_dictionary, handle)
Cleaning the bills
Let’s take a look at the text of one of the bills:
print bills_dictionary['H.R.1000 - William Howard Taft National Historic Site Boundary Adjustment Act of 2001']
[107th Congress Public Law 60]
[From the U.S. Government Printing Office]
&lt;DOC&gt;
[DOCID: f:publ060.107]
[[Page 115 STAT. 408]]
Public Law 107-60
107th Congress
An Act
To adjust the boundary of the William Howard Taft National Historic Site
in the State of Ohio, to authorize an exchange of land in connection
with the historic site, and for other purposes. &lt;&lt;NOTE: Nov. 5,
2001 - [H.R. 1000]&gt;&gt;
Be it enacted by the Senate and House of Representatives of the
United States of America in Congress &lt;&lt;NOTE: William Howard Taft
National Historic Site Boundary Adjustment Act of 2001. 16 USC 461
note.&gt;&gt; assembled,
SECTION 1. SHORT TITLE.
This Act may be cited as the ``William Howard Taft National Historic
Site Boundary Adjustment Act of 2001''.
SEC. 2. EXCHANGE OF LANDS AND BOUNDARY ADJUSTMENT, WILLIAM HOWARD TAFT
NATIONAL HISTORIC SITE, OHIO.
(a) Definitions.--In this section:
(1) Historic site.--The term ``historic site'' means the
William Howard Taft National Historic Site in Cincinnati, Ohio,
established pursuant to Public Law 91-132 (83 Stat. 273; 16
U.S.C. 461 note).
(2) Map.--The term ``map'' means the map entitled ``Proposed
Boundary Map, William Howard Taft National Historic Site,
Hamilton County, Cincinnati, Ohio,'' numbered 448/80,025, and
dated November 2000.
(3) Secretary.--The term ``Secretary'' means the Secretary
of the Interior, acting through the Director of the National
Park Service.
(b) Authorization of Land Exchange.--
(1) Exchange.--The Secretary may acquire a parcel of real
property consisting of less than one acre, which is depicted on
the map as the ``Proposed Exchange Parcel (Outside Boundary)'',
in exchange for a parcel of real property, also consisting of
less than one acre, which is depicted on the map as the
``Current USA Ownership (Inside Boundary)''.
(2) Equalization of values.--If the values of the parcels to
be exchanged under paragraph (1) are not equal, the difference
may be equalized by donation, payment using donated or
appropriated funds, or the conveyance of additional land.
(3) Adjustment of boundary.--The Secretary shall revise the
boundary of the historic site to reflect the exchange upon its
completion.
(c) Additional Boundary Revision and Acquisition Authority.--
(1) &lt;&lt;NOTE: Effective date.&gt;&gt; Inclusion of parcel in
boundary.--Effective on the date of the enactment of this Act,
the boundary of the historic site is revised to include an
additional parcel of real property, which is depicted on the map
as the ``Proposed Acquisition''.
[[Page 115 STAT. 409]]
(2) Acquisition authority.--The Secretary may acquire the
parcel referred to in paragraph (1) by donation, purchase from
willing sellers with donated or appropriated funds, or exchange.
(d) Availability of Map.--The map shall be on file and available for
public inspection in the appropriate offices of the National Park
Service.
(e) Administration of Acquired Lands.--Any lands acquired under this
section shall be administered by the Secretary as part of the historic
site in accordance with applicable laws and regulations.
Approved November 5, 2001.
LEGISLATIVE HISTORY--H.R. 1000:
---------------------------------------------------------------------------
HOUSE REPORTS: No. 107-88 (Comm. on Resources).
SENATE REPORTS: No. 107-76 (Comm. on Energy and Natural Resources).
CONGRESSIONAL RECORD, Vol. 147 (2001):
June 6, considered and passed House.
Oct. 17, considered and passed Senate.
&lt;all&gt;
Nice! This looks pretty good for a raw file. Since we’re going to use tf-idf, we need to clean the text to keep only letters. We’ll also remove stopwords (using the standard lists included in NLTK and sklearn) to remove words that provide very little information.
After cleaning, I zip the titles and clean text into a new dictionary bills_clean_dictionary and save it for quick recall.
def clean_bill(raw_bill):
"""
Function to clean bill text to keep only letters and remove stopwords
Returns a string of the cleaned bill text
"""
letters_only = re.sub('[^a-zA-Z]', ' ', raw_bill)
words = letters_only.lower().split()
stopwords_eng = set(stopwords.words("english"))
useful_words = [x for x in words if not x in stopwords_eng]
# Combine words into a paragraph again
useful_words_string = ' '.join(useful_words)
return(useful_words_string)
bills_text_list_clean = map(clean_bill, bills_text_list)
bills_clean_dictionary = dict(zip(titles_list, bills_text_list_clean))
with open(data_path + 'bills_dictionary_clean.pickle', 'wb') as handle:
pickle.dump(bills_clean_dictionary, handle)
Let’s see how the cleaned law looks:
print clean_bills_dictionary['H.R.1000 - William Howard Taft National Historic Site Boundary Adjustment Act of 2001']
th congress public law u government printing office amp lt doc amp gt docid f publ page stat public law th congress act adjust boundary william howard taft national historic site state ohio authorize exchange land connection historic site purposes amp lt amp lt note nov h r amp gt amp gt enacted senate house representatives united states america congress amp lt amp lt note william howard taft national historic site boundary adjustment act usc note amp gt amp gt assembled section short title act may cited william howard taft national historic site boundary adjustment act sec exchange lands boundary adjustment william howard taft national historic site ohio definitions section historic site term historic site means william howard taft national historic site cincinnati ohio established pursuant public law stat u c note map term map means map entitled proposed boundary map william howard taft national historic site hamilton county cincinnati ohio numbered dated november secretary term secretary means secretary interior acting director national park service b authorization land exchange exchange secretary may acquire parcel real property consisting less one acre depicted map proposed exchange parcel outside boundary exchange parcel real property also consisting less one acre depicted map current usa ownership inside boundary equalization values values parcels exchanged paragraph equal difference may equalized donation payment using donated appropriated funds conveyance additional land adjustment boundary secretary shall revise boundary historic site reflect exchange upon completion c additional boundary revision acquisition authority amp lt amp lt note effective date amp gt amp gt inclusion parcel boundary effective date enactment act boundary historic site revised include additional parcel real property depicted map proposed acquisition page stat acquisition authority secretary may acquire parcel referred paragraph donation purchase willing sellers donated appropriated funds exchange d availability map map shall file available public inspection appropriate offices national park service e administration acquired lands lands acquired section shall administered secretary part historic site accordance applicable laws regulations approved november legislative history h r house reports comm resources senate reports comm energy natural resources congressional record vol june considered passed house oct considered passed senate amp lt amp gt
Perfect! Way harder to read, but way more useful for finding textual similarities
Calculating TF-IDF Vectors
So we’ve got a dictionary of laws and their text. Now it’s time to calculate the tf-idf vectors. We’ll initialize a stemmer from NLTK to treat words like incredible and incredibly as the same token. Then we’ll initialize a TfidfVectorizer from sklearn and fit our corpus to the vectorizer. Since our corpus is all the values of the dictionary clean_bills_dictionary, we’ll pass clean_bills_dictionary.values() to the vectorizer.
stemmer = PorterStemmer()
def stem_words(words_list, stemmer):
return [stemmer.stem(word) for word in words_list]
def tokenize(text):
tokens = nltk.word_tokenize(text)
stems = stem_words(tokens, stemmer)
return stems
tfidf = TfidfVectorizer(tokenizer=tokenize, stop_words='english')
tfs = tfidf.fit_transform(clean_bills_dictionary.values())
So what do we actually have now? tfs should be a matrix, where each row represents a law and each column represents a token (word) in the corpus. Let’s see if we’re right.
tfs
<3725x30894 sparse matrix of type '<type 'numpy.float64'>'
with 1125934 stored elements in Compressed Sparse Row format>
Perfect. It’s a sparse numpy array because it’s essentially a matrix of zeros, with a handful of nonzero elements per row. The sparse matrix format is more efficient storage wise. Let’s save the sparse matrix so we won’t have to recalculate it. These functions (from the Scipy user group) let us easily save and load the array.
from scipy.sparse import csr_matrix
def save_sparse_csr(filename,array):
np.savez(filename,data = array.data ,indices=array.indices,
indptr =array.indptr, shape=array.shape )
def load_sparse_csr(filename):
loader = np.load(filename)
return csr_matrix((loader['data'], loader['indices'], loader['indptr']),
shape = loader['shape'])
save_sparse_csr(data_path + 'laws_tf_idf.npz', tfs)
Finding a Law’s Nearest Neighbors with Cosine Distance
Finally, we can find similar laws! We’ll initialize a NearestNeighbors class and fit our tf-idf matrix to it. Since we want to use cosine distance as our distance metric, I’ll initialize it with metric='cosine'.
from sklearn.neighbors import NearestNeighbors
model_tf_idf = NearestNeighbors(metric='cosine', algorithm='brute')
model_tf_idf.fit(tfs)
Let’s define a function to print the k nearest neighbors for any query law. Since we have our corpus stored as a dictionary, we’ll define the function to take the dictionary as an input.
def print_nearest_neighbors(query_tf_idf, full_bill_dictionary, knn_model, k):
"""
Inputs: a query tf_idf vector, the dictionary of bills, the knn model, and the number of neighbors
Prints the k nearest neighbors
"""
distances, indices = knn_model.kneighbors(query_tf_idf, n_neighbors = k+1)
nearest_neighbors = [full_bill_dictionary.keys()[x] for x in indices.flatten()]
for bill in xrange(len(nearest_neighbors)):
if bill == 0:
print 'Query Law: {0}\n'.format(nearest_neighbors[bill])
else:
print '{0}: {1}\n'.format(bill, nearest_neighbors[bill])
Time to test it! I’ll pick a couple random laws and find their nearest neighbors.
bill_id = np.random.choice(tfs.shape[0])
print_nearest_neighbors(tfs[bill_id], clean_bills_dictionary, model_tf_idf, k=5)
Query Law: H.R.2517 - Protecting Our Children Comes First Act of 2007
1: H.R.3209 - Recovering Missing Children Act
2: S.1738 - PROTECT Our Children Act of 2008
3: S.249 - Missing, Exploited, and Runaway Children Protection Act
4: H.R.3092 - E. Clay Shaw, Jr. Missing Children's Assistance Reauthorization Act of 2013
5: S.151 - PROTECT Act
bill_id = np.random.choice(tfs.shape[0])
print_nearest_neighbors(tfs[bill_id], clean_bills_dictionary, model_tf_idf, k=5)
Query Law: H.R.539 - Caribbean National Forest Act of 2005
1: S.4001 - New England Wilderness Act of 2006
2: H.R.4750 - Big Sur Wilderness and Conservation Act of 2002
3: H.R.233 - Northern California Coastal Wild Heritage Wilderness Act
4: S.503 - Spanish Peaks Wilderness Act of 2000
5: H.R.15 - Otay Mountain Wilderness Act of 1999
Pretty good! Remember, we didn’t use the title of the laws in the analysis. These rankings are just based on the textual similarity. Since the nearest neighbors seem to be decent, let’s try some k-means clustering.
Clustering with K-Means
With the groundwork already in place, all we have to do is implement the k-means model. Ideally, we’d choose the number of clusters based on domain knowledge. We could also use one of a variety of techniques to find a “good” number of clusters such as using the Gap Statistic or the Elbow Method. The Elbow Method is a simple, but effective, way to tune the k parameter. Essentially, we calculate the within-cluster sum of squared error (which decreases as k increases by definition) and pick the k as the value when we stop getting large decreases in the within-cluster sum of squares. However, for simplicity, I’ll just set k = 50 – that seems fine to me for this blog post.
tfs = load_sparse_csr(data_path + 'laws_tf_idf.npz')
To implement k-means, we initialize the KMeans class from sklearn.cluster as km and fit our tf-idf matrix tfs to the KMeans instance.
from sklearn.cluster import KMeans
k = 50
km = KMeans(n_clusters=k, init='k-means++', max_iter=100, n_init=5,
verbose=1)
km.fit(tfs)
Let’s look at the cluster assignments. What’s the distribution of cluster assignments?
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(km.labels_, bins=k)
plt.show()
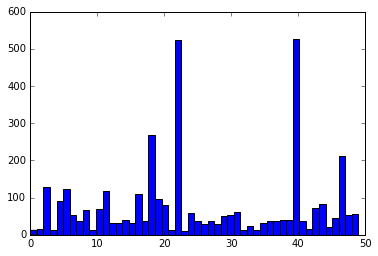
So it’s not uniformly distributed (which makes sense), but it’s also not exatly obvious that 50 was a good choice of k. Oh well! Good enough to push forward. Let’s assign the bills to their clusters and see if they make sense. We’ll create a dictionary with the clusters as keys and the laws as values assigned to their respective clusters.
cluster_assignments_dict = {}
for i in set(km.labels_):
#print i
current_cluster_bills = [clean_bills_dictionary.keys()[x] for x in np.where(km.labels_ == i)[0]]
cluster_assignments_dict[i] = current_cluster_bills
Let’s take a look at a couple random clusters.
cluster_pick = np.random.choice(len(set(km.labels_)))
print 'Cluster {0}'.format(cluster_pick)
cluster_assignments_dict[cluster_pick]
Cluster 41
['H.R.2719 - Transportation Security Acquisition Reform Act',
'H.R.1626 - DHS IT Duplication Reduction Act of 2015',
'H.R.1801 - Risk-Based Security Screening for Members of the Armed Forces Act',
'S.2516 - Kendell Frederick Citizenship Assistance Act',
'H.R.3068 - Federal Protective Service Guard Contracting Reform Act of 2008',
'H.R.3978 - First Responder Anti-Terrorism Training Resources Act',
'H.R.3801 - Ultralight Aircraft Smuggling Prevention Act of 2012',
'S.3542 - No-Hassle Flying Act of 2012',
'S.1638 - Department of Homeland Security Headquarters Consolidation Accountability Act of 2015',
'H.R.3210 - Pay Our Military Act',
'H.R.915 - Jaime Zapata Border Enforcement Security Task Force Act',
'H.R.2952 - Cybersecurity Workforce Assessment Act',
'H.R.4954 - SAFE Port Act',
'H.R.615 - DHS Interoperable Communications Act',
'H.R.553 - Reducing Over-Classification Act',
'S.1447 - Aviation and Transportation Security Act',
'S.2519 - National Cybersecurity Protection Act of 2014',
'H.R.4259 - Department of Homeland Security Financial Accountability Act',
'H.R.4007 - Protecting and Securing Chemical Facilities from Terrorist Attacks Act of 2014',
'H.R.4748 - Northern Border Counternarcotics Strategy Act of 2010',
'H.R.3116 - Quarterly Financial Report Reauthorization Act',
'S.1487 - Asia-Pacific Economic Cooperation Business Travel Cards Act of 2011',
'H.R.1204 - Aviation Security Stakeholder Participation Act of 2014',
'S.1691 - Border Patrol Agent Pay Reform Act of 2014',
'H.R.2835 - Border Jobs for Veterans Act of 2015',
'S.2440 - Airport Security Improvement Act of 2000',
'S.2816 - A bill to provide for the appointment of the Chief Human Capital Officer of the Department of Homeland Security by the Secretary of Homeland Security.',
'H.R.4119 - Border Tunnel Prevention Act of 2012',
'S.1998 - DART Act',
'H.R.6080 - Making emergency supplemental appropriations for border security for the fiscal year ending September 30, 2010, and for other purposes.',
'S.3243 - Anti-Border Corruption Act of 2010',
'H.R.3606 - Jumpstart Our Business Startups',
'S.2521 - Federal Information Security Modernization Act of 2014',
'H.R.1 - Implementing Recommendations of the 9/11 Commission Act of 2007',
'H.R.720 - Gerardo Hernandez Airport Security Act of 2015',
'H.R.623 - DHS Social Media Improvement Act of 2015',
'H.R.6098 - PRICE of Homeland Security Act',
'H.R.6061 - Secure Fence Act of 2006']
Okay, so cluster 41 seems to have mostly laws about US security. Let’s pick another random cluster
cluster_pick = np.random.choice(len(set(km.labels_)))
print 'Cluster {0}'.format(cluster_pick)
cluster_assignments_dict[cluster_pick]
Cluster 27
['S.3397 - Secure and Responsible Drug Disposal Act of 2010',
'H.R.1321 - Microbead-Free Waters Act of 2015',
'S.3560 - QI Program Supplemental Funding Act of 2008',
'H.R.1132 - National All Schedules Prescription Electronic Reporting Act of 2005',
'H.R.2751 - FDA Food Safety Modernization Act',
'H.R.4679 - Antimicrobial Regulation Technical Corrections Act of 1998',
'S.313 - Animal Drug User Fee Act of 2003',
'H.R.3204 - Drug Quality and Security Act',
'H.R.5651 - Medical Device User Fee and Modernization Act of 2002',
'S.3187 - Food and Drug Administration Safety and Innovation Act',
'S.3546 - Dietary Supplement and Nonprescription Drug Consumer Protection Act',
'S.650 - Pediatric Research Equity Act of 2003',
'H.R.3633 - Controlled Substances Trafficking Prohibition Act',
'H.R.4771 - Designer Anabolic Steroid Control Act of 2014',
'S.1395 - Controlled Substances Export Reform Act of 2005',
'S.524 - Comprehensive Addiction and Recovery Act of 2016',
'H.R.1256 - Family Smoking Prevention and Tobacco Control Act',
'S.1789 - Best Pharmaceuticals for Children Act',
'H.R.2291 - To extend the authorization of the Drug-Free Communities Support Program for an additional 5 years, to authorize a National Community Antidrug Coalition Institute, and for other purposes.',
'H.R.639 - Improving Regulatory Transparency for New Medical Therapies Act',
'H.R.3423 - Medical Device User Fee Stabilization Act of 2005',
'H.R.6432 - To amend the Federal Food, Drug, and Cosmetic Act to revise and extend the animal drug user fee program, to establish a program of fees relating to generic new animal drugs, to make certain technical corrections to the Food and Drug Administration Amendments Act of 2007, and for other purposes.',
'H.R.2130 - Hillory J. Farias and Samantha Reid Date-Rape Drug Prohibition Act of 2000',
'H.R.6433 - FDA User Fee Corrections Act of 2012',
'H.R.2576 - Frank R. Lautenberg Chemical Safety for the 21st Century Act',
'H.R.6353 - Ryan Haight Online Pharmacy Consumer Protection Act of 2008',
'S.3552 - Pesticide Registration Improvement Extension Act of 2012',
'S.32 - Transnational Drug Trafficking Act of 2015',
'S.741 - Minor Use and Minor Species Animal Health Act of 2003 ',
'S.764 - A bill to reauthorize and amend the National Sea Grant College Program Act, and for other purposes.',
'S.2141 - Sunscreen Innovation Act',
'S.1789 - Fair Sentencing Act of 2010',
'H.R.3580 - Food and Drug Administration Amendments Act of 2007',
'S.622 - Animal Drug and Animal Generic Drug User Fee Reauthorization Act of 2013',
'H.R.4014 - Rare Diseases Orphan Product Development Act of 2002',
'H.R.6344 - Office of National Drug Control Policy Reauthorization Act of 2006',
'S.172 - A bill to amend the Federal Food, Drug, and Cosmetic Act to provide for the regulation of all contact lenses as medical devices, and for other purposes.',
'S.483 - Ensuring Patient Access and Effective Drug Enforcement Act of 2016']
Cluster 27 looks pretty tight also - lots of bills about food, drugs, and medicine. Nice! We’ve got some decent clusters, and we try to figure out the themes by looking at the titles of the laws. But can we do better than just looking at the titles?
Determining Cluster Themes with TF-IDF
What if we reverse engineered the cluster “themes” from the text of the laws by employing tf-idf again? Within any single cluster, we have a set of laws. If we calculate the inverse document frequencies for all of the words in the cluster’s corpus, we’ll know which words should provide the least weight. Essentially, the lowest idf-weight words should correspond to the general themes present in most of the documents.
Since so many laws have United States in them, we’ll add those words to the set of stopwords. Then we can just clean each cluster’s laws again, estimate the idf weights for the cluster, and see if the lowest weighted terms show any general themes. Since apparently I can’t stop using dictionaries, we’ll store the bottom 5 words in the dictionary cluster_themes_dict.
def clean_bill(raw_bill):
"""
Function to clean bill text to keep only letters and remove stopwords
Returns a string of the cleaned bill text
"""
letters_only = re.sub('[^a-zA-Z]', ' ', raw_bill)
words = letters_only.lower().split()
stopwords_eng = set(stopwords.words("english"))
stopwords_updated = stopwords_eng.add(u'united')
stopwords_updated = stopwords_eng.add(u'states')
useful_words = [x for x in words if not x in stopwords_eng]
# Combine words into a paragraph again
useful_words_string = ' '.join(useful_words)
return(useful_words_string)
cluster_themes_dict = {}
for key in cluster_assignments_dict.keys():
current_tfidf = TfidfVectorizer(tokenizer=tokenize, stop_words='english')
current_tfs = current_tfidf.fit_transform(map(clean_bill, cluster_assignments_dict[key]))
current_tf_idfs = dict(zip(current_tfidf.get_feature_names(), current_tfidf.idf_))
tf_idfs_tuples = current_tf_idfs.items()
cluster_themes_dict[key] = sorted(tf_idfs_tuples, key = lambda x: x[1])[:5]
Sweet. Let’s look at clusters 27 and 41 again.
print 'Cluster 27 key words: {0}'.format([x[0] for x in cluster_themes_dict[27]])
print 'Cluster 41 key words: {0}'.format([x[0] for x in cluster_themes_dict[41]])
Cluster 27 key words: [u'act', u'drug', u'fee', u'user', u'food']
Cluster 41 key words: [u'act', u'security', u'border', u'homeland', u'reform']
Those looks great! The laws in cluster 27 are generally about food and drugs, and the ones in cluster 41 are about security. The laws in these clusters appear linearly separable in this 30894-dimensional space. Looks like using inverse document frequency to recover cluster themes might be pretty effective. But do we really believe we can create 50 well separated clusters in this space?
Visualizing the Laws as TF-IDF Vectors using t-SNE
How can we “squeeze” the information contained in the high dimensional space down to an array in R2, which we can visualize easily with a scatter plot. One way is Principal Components Analysis. Another way is t-SNE, or t-distributed Stochastic Neighbor Embedding. t-SNE is an extension of SNE. So what is SNE?
In their t-SNE paper, van der Maaten and Hinton describe the core of stochastic neighbor embedding as:
1) “Estimating the similarity of datapoint xj to datapoint xi is the conditional probability, pj|i, that xi would pick xj as its neighbor if neighbors were picked in proportion to their probability density under a Gaussian centered at xi.”
2) “For the low-dimensional counterparts yi and yj of the high-dimensional datapoints xi and xj, it is possible to compute a similar conditional probability, which we denote by qj|i.”
3) “Find a low-dimensional data representation that minimizes the mismatch between pj|i and qj|i.”
So we’re essentially minimizing a cost function with gradient descent to find a low dimensional data representation that keeps “close” points together in the new dimensions. Cool. Let’s do it.
First we’ll decompose our tf-idf matrix tfs into a lower dimensional space since most of our space is empty.
from sklearn.manifold import TSNE
from sklearn.decomposition import TruncatedSVD
k = 50
tfs_reduced = TruncatedSVD(n_components=k, random_state=0).fit_transform(tfs)
Next, we’ll find a 2-D representation of our 50-dimensional data using t-SNE.
tfs_embedded = TSNE(n_components=2, perplexity=40, verbose=2).fit_transform(tfs_reduced)
With our vector embeddings in hand, let’s plot the laws colored according to their k-means cluster assignment.
fig = plt.figure(figsize = (10, 10))
ax = plt.axes()
plt.scatter(tfs_embedded[:, 0], tfs_embedded[:, 1], marker = "x", c = km.labels_)
plt.show()
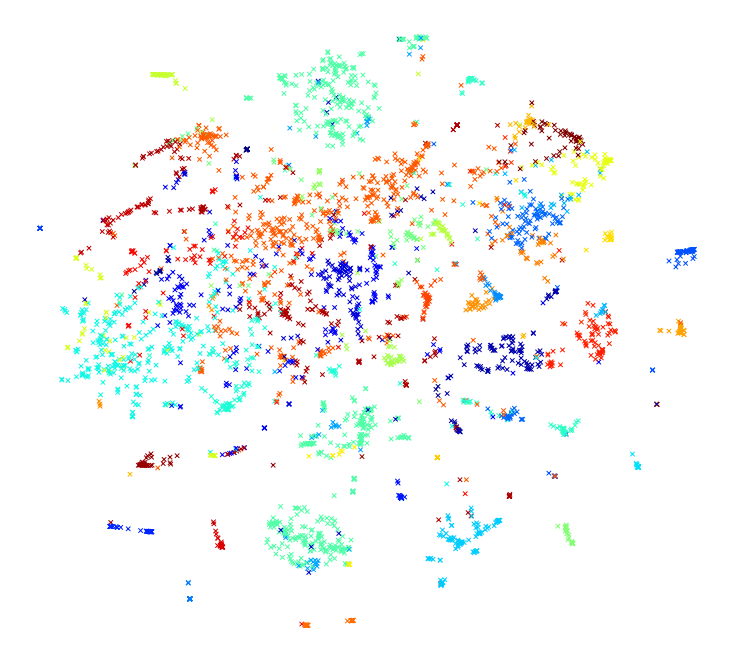
Not too bad! We can see some clusters are mostly on their own, while some are intermingled with other clusters. Considering we picked k = 50 arbitrarily, I’d say this is a pretty good result.
Leave a Comment